
Nodejs 爬蟲教學 (cheerio)- 以 CPBL 官網賽程為例
延續前一篇實作 TPBL Fantasy 心得,這篇更專注在爬蟲的實作,需要爬蟲的情境是當你需要某個類型的資料,但有那個網站的資料並沒有 Open API
說到這邊一定要靠杯一下幾年前看過政府的某個黑客松,裡面的 Open API 居然有 PDF 格式的
所謂的 Open API,要可以提供一個機器可以讀得懂的介面,以及機器可以方便閱讀,有規律的資料格式,所以網站有提拱 PDF, Word,並不等同於是 Open API
必備知識
- 網路知識
- 知道怎麼用 chrome 的 devtool 觀察網站怎麼運作
- 知道怎麼用 Nodejs
- 知道怎麼用 css (selector 的部份)
觀察 CPBL 官網賽程的結構
先按右鍵,選檢視網頁原始碼,確定是 SSR
簡單分辨 SSR 或 CSR 就是在看原始碼時,網頁可視內容跟原始碼內容大小有沒有差太多 (雖然有些網站是混用)
然後打開 DevTool 的 Elements tab
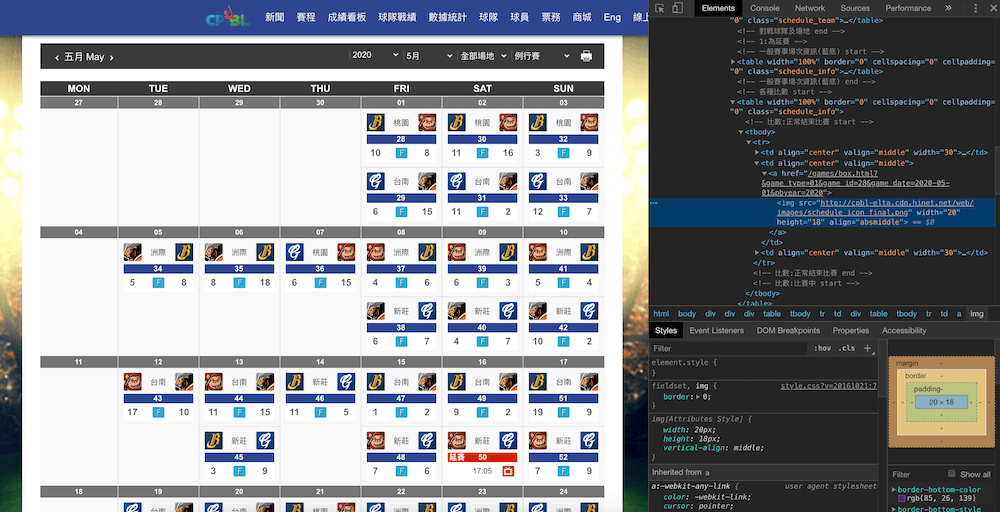
在同一個 tab,按下 Cmd+F (windows 是 Ctrl+F) 搜尋 .one_block,會找到這個月份 44 場比賽,這邊要特別講一下,因為 Chrome 會自動補齊網站原始碼不完整的部份,所以有時候在 devtool 沒問題,但在爬蟲程式就會找不到,如果發現有這種情況,記得要按 view source 看一下差異
WARNING: It may burn your eyes
然後展開 .one_block 可以看到以下結構
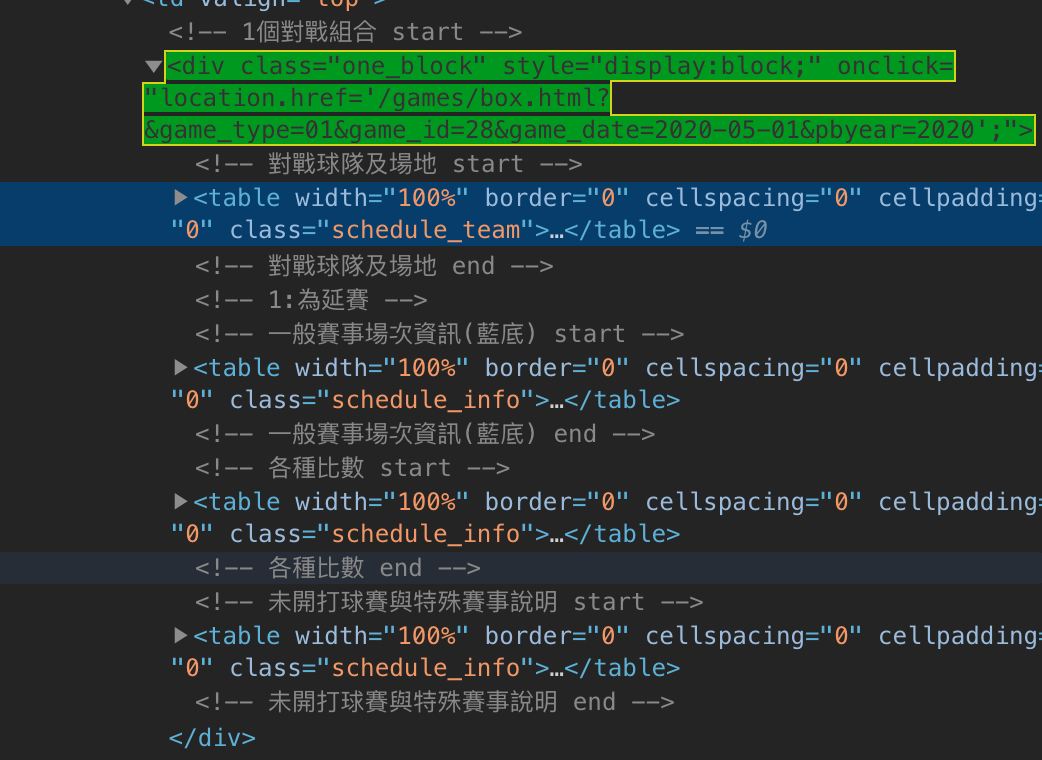
看到這邊差不多可以開始實作了
開始實作爬蟲
接下來可以開始動手了,首先準備好環境
1 | mkdir ./web-scraper && cd ./web-scraper |
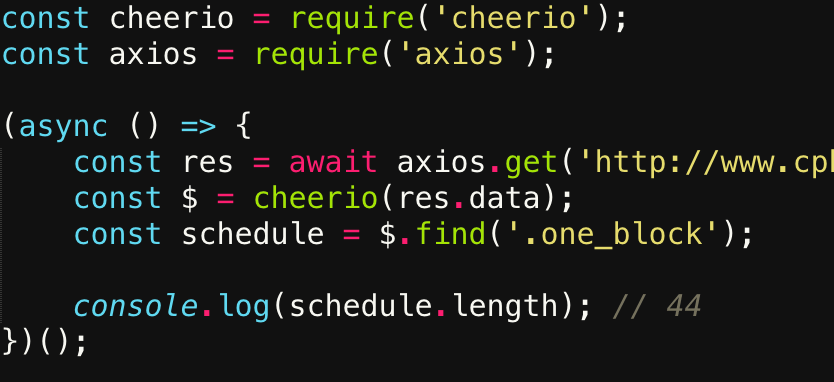
然後用剛觀察到的 selector 去取得全部的賽程
用 map 取得每場的資訊
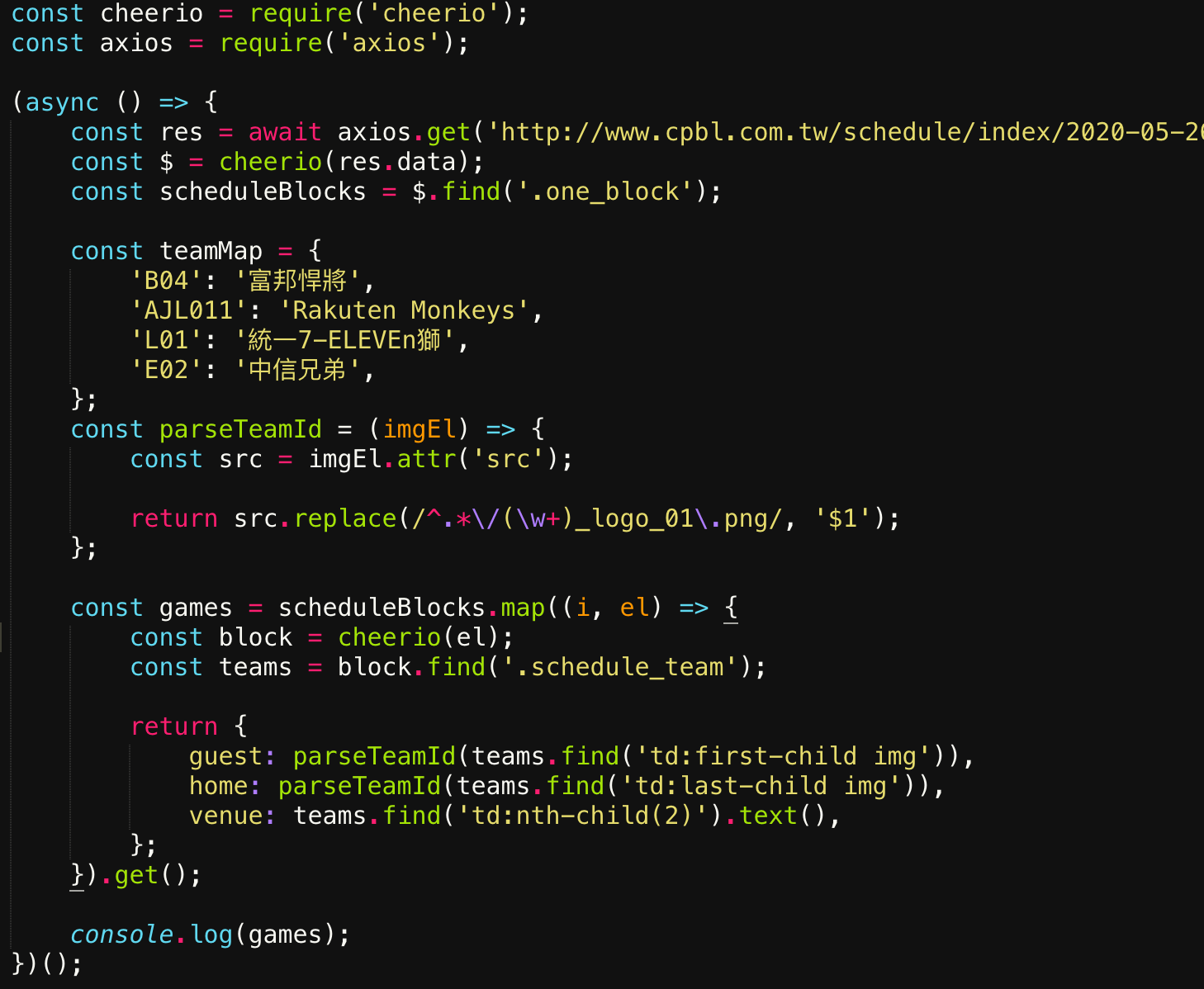
因為隊伍是用圖片示意,沒辦法直接取得文字,只好轉個彎,改用圖片的網址去 parse
抓得到東西不難,穩定的抓得到東西才難
以下有些爬蟲的進階狀況
被網站擋了
一般有規模的網站,會有防止 ddos 的機制,所以如果太過頻繁存取的話,ip 會被直接擋掉。除了買 proxy 之外,也可以試試用 tor (安裝看這裡),不過通常抓東西不要太密集會比較好啦,不然不小心把網站弄掛就得不償失
另外有一種擋 ip 的做法是在 application 層,以下是常見的做法 (php):
1 | if (!empty($_SERVER['HTTP_CLIENT_IP'])) { |
這做法邏輯上沒錯,但問題是所有來自 client 端的資料都可以被竄改,例如 (以 axios):
1 | const response = axios({ |
有好多東西要抓
通常要配合前段一起做,才不會被擋,如果不用的話……這網站大概沒什麼人在管,總之可以先蒐集內部相關網址,然後配合 MessageQueue 循序去抓,至於要用哪個 MessageQueue? 就看個人喜好
如果想試的話,可以先從這個範本開始